At some point in every production incident, someone opens the logs and discovers they don’t say anything useful.
The logs are there. The application was definitely logging. But what’s in front of you is a wall of [INFO] Processing request, a handful of timestamps, and an HTTP 500 with no message attached. Payments are failing. Nobody knows why. The team is now guessing — cross-referencing memory, checking recent deployments, staring at a dashboard that confirms something is wrong without explaining what.
The code had logging. It just wasn’t written for this moment.
You’re writing logs for the wrong person
When you write a log statement during development, you’re writing it for yourself. You know what the code does, you know what context matters, and you’re reading the output seconds after it’s produced in a local environment where you can immediately do something about it.
In production, the reader is different. It might be an on-call engineer who didn’t write this service. It might be you — six months later, at 11pm, with no memory of this code path. It might be a support team member trying to diagnose a customer-reported issue without access to the code.
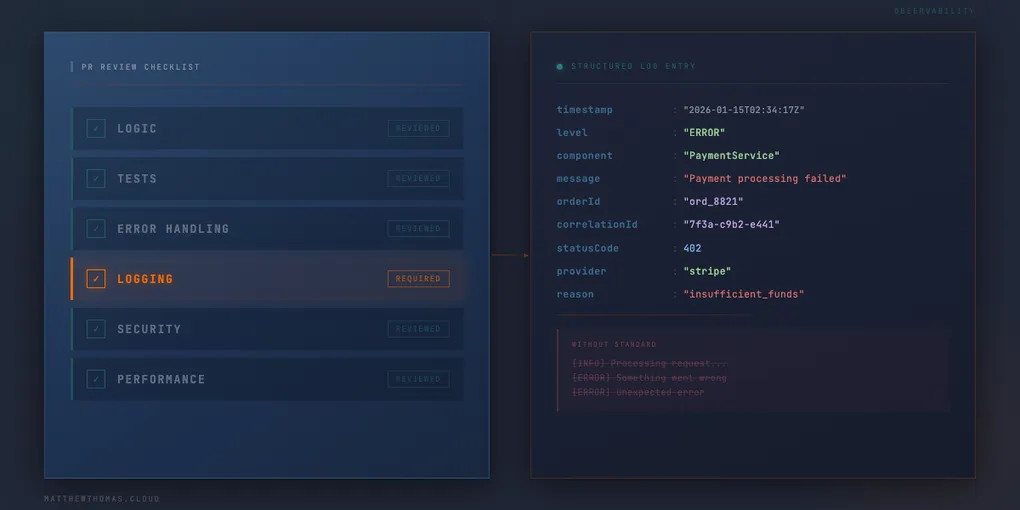
That person needs to know: what happened, what state the system was in when it happened, and whether they should care. A log entry that reads Error occurred in PaymentService answers none of those questions. A log entry that reads Payment processing failed | orderId=8821 | customerId=4492 | provider=Stripe | statusCode=402 | reason=insufficient_funds answers all of them.
The difference isn’t the volume of logging. It’s whether the log was written for the developer or for the incident.
What bad logging actually looks like
Bad logging takes a few forms, and they’re easy to miss during review because none of them cause a compilation error or a failing test.
The most common is the vague message - "Something went wrong", "Unexpected error", "Request failed". These tell you a problem happened, which you already knew because something is on fire. They don’t tell you where, why, or what to do next.
The second is wrong log levels. An exception logged at DEBUG is invisible in production, because production environments usually run at INFO or above. A noisy third-party library flooding ERROR means the real errors disappear into the noise. Levels are a contract - if your team doesn’t have a shared understanding of what each one means, every developer will use them differently and the signal becomes meaningless.
The third, and the one that causes the most pain, is swallowed context. An exception caught, a generic message logged, and the original exception details discarded. Or a failed HTTP call logged with the status code but not the response body. Or a failure with no correlation ID, so you can’t trace it back to the originating request in a distributed system.
None of this shows up in tests. It shows up when something breaks in production and you’re trying to reconstruct what happened.
Why it never gets caught
PR reviews focus on the things that are obviously reviewable: logic, test coverage, structure, edge cases. Logging doesn’t feel like logic, it feels like instrumentation, and instrumentation feels optional.
Nobody pushes back on a missing log statement the way they’d push back on a missing null check. There’s no red squiggle, no lint rule, no test failure. A reviewer has to consciously think to look for it, and most don’t because there’s no prompt to do so.
The result is that logging is added reactively, after the first incident that revealed a gap, or inconsistently, because every developer makes different judgements about what’s worth capturing and how. Over time you end up with a system where some paths are well-instrumented and others are dark, and you only find out which is which when something goes wrong.
Making it a requirement
The fix is to stop treating logging as a nice-to-have and start treating it like test coverage, something that gets reviewed, something there’s a standard for, something that can block a merge.
The first step is a standard. Agree on what each log level means for your team. Agree on the fields that structured log entries must include: correlation ID, component, operation, any domain identifiers that would help trace a request. Agree on what always gets logged: every external call outcome, every failure path, every significant state transition. Be explicit about what doesn’t need logging too, not every change touches a new code path, and your standard should say so before every PR becomes a debate about whether it applies.
The second step is making that standard visible in the review process. Add logging to your PR checklist, not as an optional note but as a required check. Does the new code have appropriate logging? Are failure paths covered? Is the level right? Does a log entry contain enough context to be useful to someone who wasn’t in the room when this was written?
For teams that use AI in their review process, this is a reasonable thing to automate. An LLM can scan a diff and ask whether new code paths have corresponding log statements, whether exceptions are logged with full context, whether HTTP calls log the outcome. It won’t catch everything, but it adds a layer of scrutiny that currently doesn’t exist.
Some things can go further; linting rules for log levels, required-field validation for structured log schemas, build gates that fail on certain patterns. How far you take it depends on the team and the tooling. But the baseline, logging as part of review, with a documented standard, costs almost nothing and pays off the first time an incident gets resolved in minutes instead of hours because the logs actually said something.
It’s a first-class concern
Logging isn’t decoration. It’s the interface between your application and whoever has to operate it. If that interface is poorly designed, the operational cost shows up every time something goes wrong; in longer incidents, more guesswork, and engineers who’ve learned not to trust the logs anyway.
The same care that goes into API design, data modelling, and error handling should go into what you log and how. Start reviewing it. Make it part of the standard. The on-call engineer at 2am, which might be you, will thank you.
I’d be curious whether logging makes it into PR reviews on your team, or whether this is one of those things that only gets addressed after an incident. Let me know on LinkedIn 🔗.
