Something breaks in production. Alerts and Teams go nuts. Someone says “let’s just do a hotfix” – half an hour later, the system is back up. Great? Right? Not really…
Everyone is happy, the system is back up, the customer isn’t shouting at you. But then the real issues start to arise. What about testing? What about a proper RCA? Now our branches are out of sync.
What I’m trying to say is, hotfixes are not that hot. Yes, they get the system back up — but the real cost shows up days later, in your branches, your pipeline, and your team’s habits.
The problem with hotfixes in the flow
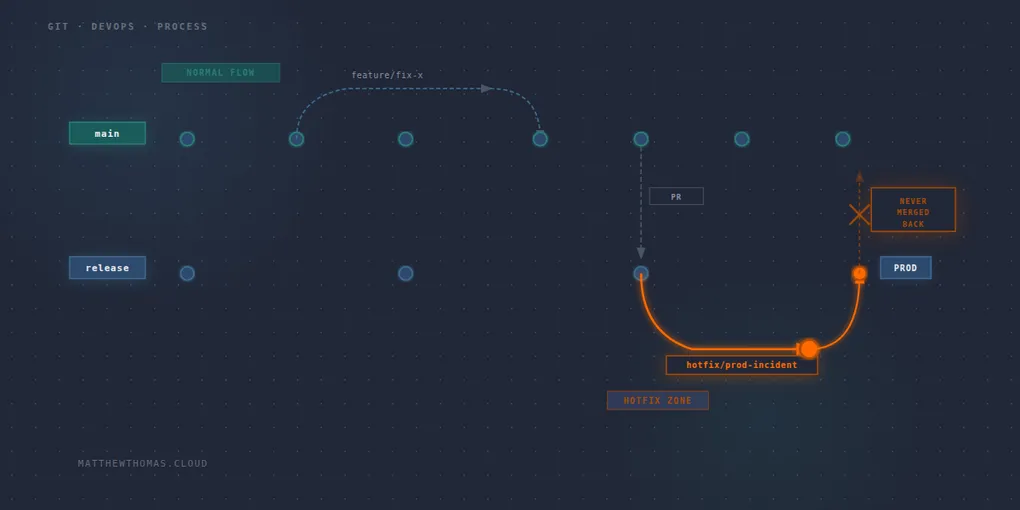
When you create a hotfix, you branch from release, not main. There’s the start of the problem. The fix goes back into the release branch and gets deployed - main doesn’t know about it. The branches are out of sync from minute one.
The next PR into release is either going to overwrite that fix or create a conflict someone needs to unpick.
You’re meant to merge back to main after the dust has settled. In practice, it gets skipped more often than anyone wants to admit. Post-incident there’s a retrospective to run, a backlog to catch up on, and a PR sitting in a queue that nobody feels urgency around anymore.
The testing gap
The normal flow has gates in it for a reason. Feature branch, pull request, merge to main, PR to release, pipeline stages. Each step is a chance to catch something before it reaches production.
The hotfix skips most if not all of that. You’re getting shouted at that “it’s urgent” and the pressure is on to get it fixed fast.
Now I’m not saying that there won’t be times when you really do need to get that fix out in twenty minutes – but it really should not be the norm. But the threshold for what counts as urgent drifts downward over time. The first hotfix was genuinely critical. The fifth one is a customer-facing bug that probably could have waited for a proper PR cycle.
The regressions that follow don’t announce themselves as an issue. They show up a week later, in a different part of the system, and nobody connects the dots back to the fix that skipped testing.
The cultural cost
Every process has friction in it deliberately. Review gates, pipeline stages, approval steps — these exist because shipping software is risky and the friction is doing work. A hotfix is a fast lane that bypasses that friction, and fast lanes change behaviour.
Once a shortcut exists, the incentive to not need it erodes. Not dramatically, not all at once. But if your team is running multiple hotfixes, you’re not operating a hotfix process – that has become an informal release process for when you’re being shouted at and nobody consciously decided to build it.
What can you do about it? Have a definition of what qualifies as a hotfix and have it documented before the incident happens. That way, when there is an incident, you have that definition to fall back to in order to make a decision of the path to fix.
Audit, compliance, and accountability
A proper root cause analysis should follow every production incident. These are a learning opportunity, not a blame exercise. Hotfixes make RCAs easy to skip. The system is back up, the pressure has lifted, and there’s always something more pressing.
No RCA means no real understanding of why it happened. Which means it’ll happen again. In regulated industries — insurance, financial services — there’s usually a paper trail requirement too. A hotfix with no review sign-off, no documented rationale, and no record of what changed is an audit risk. “We fixed it” is not the same as “we understand why it happened and have evidence that we do.”
What good looks like
The first instinct when something breaks in production should be roll back, not fix. Get the system back to a known good state. That buys you time – time to understand what actually went wrong, reproduce it safely, and fix it properly through your normal process. If you can’t roll back, ask whether you can toggle a feature flag off. Sometimes that thing that breaks can’t be properly flagged – that happens – but the more you lean on flags, the more you protect yourself.
A rollback isn’t admitting defeat. It’s professional. It decouples “system is back up” from “fix is ready”, and that separation matters.
If rollback genuinely isn’t possible — and sometimes it isn’t — then a hotfix is the answer. But the change should be the minimum viable fix. Not a refactor, not a cleanup, not “while we’re in here” improvements. Just the change required to address the specific problem.
After that: merge back to main before the incident is formally closed. Not “when someone gets to it.” Before it’s closed. And the RCA is part of closing the incident, not optional follow-up that quietly doesn’t happen.
Every hotfix is a signal. Something in the normal process didn’t catch this. That’s worth understanding.
Where we want to get to
The goal isn’t a better hotfix process — it’s making hotfixes rare enough that they feel like the exception they’re supposed to be. If you’re doing a hotfix, and you can remember the last one, that’s something you need to pay attention to.
That means investing in rollback until it’s fast, reliable, and boring. If rolling back is always the obvious first move, hotfixes become genuinely last-resort. It means better test coverage, so the gate that should have caught this actually does. And it means feature flags — ship the fix, control the exposure, decouple deployment from release entirely.
The measure of a mature deployment process isn’t how well you hotfix. It’s how rarely you need to.
